
1. 案例扩展
1.1 定时任务
在案例中我们使用的是Spring内置的Spring Task,这是Spring3.0加入的定时任务功能。我们使用注解的方式定时启动爬虫进行数据爬取。
我们使用的是@Scheduled注解,其属性如下:
- cron:cron表达式,指定任务在特定时间执行;
- fixedDelay:上一次任务执行完后多久再执行,参数类型为long,单位ms
- fixedDelayString:与fixedDelay含义一样,只是参数类型变为String
- fixedRate:按一定的频率执行任务,参数类型为long,单位ms
- fixedRateString: 与fixedRate的含义一样,只是将参数类型变为String
- initialDelay:延迟多久再第一次执行任务,参数类型为long,单位ms
- initialDelayString:与initialDelay的含义一样,只是将参数类型变为String
- zone:时区,默认为当前时区,一般没有用到
我们这里的使用比较简单,固定的间隔时间来启动爬虫。例如可以实现项目启动后,每隔一小时启动一次爬虫。
但是有可能业务要求更高,并不是定时定期处理,而是在特定的时间进行处理,这个时候我们之前的使用方式就不能满足需求了。例如我要在工作日(周一到周五)的晚上八点执行。这时我们就需要Cron表达式了。
1.1.1 Cron表达式
cron的表达式是字符串,实际上是由七子表达式,描述个别细节的时间表。这些子表达式是分开的空白,代表:
1、Seconds
2、Minutes
3、Hours
4、Day-of-Month
5、Month
6、Day-of-Week
7、Year (可选字段)
例 “0 0 12 ? * WED” 在每星期三下午12:00 执行, “*” 代表整个时间段
每一个字段都有一套可以指定有效值,如
Seconds (秒) :可以用数字0-59 表示,
Minutes(分) :可以用数字0-59 表示,
Hours(时) :可以用数字0-23表示,
Day-of-Month(天) :可以用数字1-31 中的任一一个值,但要注意一些特别的月份
Month(月) :可以用0-11 或用字符串:JAN, FEB, MAR, APR, MAY, JUN, JUL, AUG, SEP, OCT, NOV, DEC
Day-of-Week(天) :可以用数字1-7表示(1 = 星期日)或用字符口串:SUN, MON, TUE, WED, THU, FRI, SAT
“/”:为特别单位,表示为“每”如“0/15”表示每隔15分钟执行一次,“0”表示为从“0”分开始, “3/20”表示表示每隔20分钟执行一次,“3”表示从第3分钟开始执行
“?”:表示每月的某一天,或第周的某一天
“L”:用于每月,或每周,表示为每月的最后一天,或每个月的最后星期几如“6L”表示“每月的最后一个星期五”
1.1.2 Cron测试
1 | /** |
1.2 网页去重
之前我们对下载的url地址进行了去重操作,避免同样的url下载多次。其实不光url需要去重,我们对下载的内容也需要去重。
在网上我们可以找到许多内容相似的文章。但是实际我们只需要其中一个即可,同样的内容没有必要下载多次,那么如何进行去重就需要进行处理了
1.2.1 去重方案介绍
指纹码对比
最常见的去重方案是生成文档的指纹门。例如对一篇文章进行MD5加密生成一个字符串,我们可以认为这是文章的指纹码,再和其他的文章指纹码对比,一致则说明文章重复。
但是这种方式是完全一致则是重复的,如果文章只是多了几个标点符号,那仍旧被认为是重复的,这种方式并不合理。
BloomFilter
这种方式就是我们之前对url进行去重的方式,使用在这里的话,也是对文章进行计算得到一个数,再进行对比,缺点和方法1是一样的,如果只有一点点不一样,也会认为不重复,这种方式不合理。
KMP算法
KMP算法是一种改进的字符串匹配算法。KMP算法的关键是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。能够找到两个文章有哪些是一样的,哪些不一样。
这种方式能够解决前面两个方式的“只要一点不一样就是不重复”的问题。但是它的时空复杂度太高了,不适合大数据量的重复比对。
还有一些其他的去重方式:最长公共子串、后缀数组、字典树、DFA等等,但是这些方式的空复杂度并不适合数据量较大的工业应用场景。我们需要找到一款性能高速度快,能够进行相似度对比的去重方案
Google 的 simhash 算法产生的签名,可以满足上述要求。这个算法并不深奥,比较容易理解。这种算法也是目前Google搜索引擎所目前所使用的网页去重算法。
1.2.2 SimHash
1.2.2.1 流程介绍
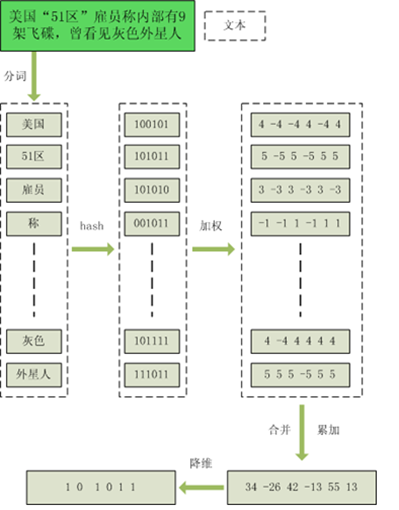
simhash是由 Charikar 在2002年提出来的,为了便于理解尽量不使用数学公式,分为这几步:
1、分词,把需要判断文本分词形成这个文章的特征单词。
2、hash,通过hash算法把每个词变成hash值,比如“美国”通过hash算法计算为 100101,“51区”通过hash算法计算为 101011。这样我们的字符串就变成了一串串数字。
3、加权,通过 2步骤的hash生成结果,需要按照单词的权重形成加权数字串,“美国”的hash值为“100101”,通过加权计算为“4 -4 -4 4 -4 4”,“51区”计算为 “ 5 -5 5 -5 5 5”。
4、合并,把上面各个单词算出来的序列值累加,变成只有一个序列串。 “美国”的 “4 -4 -4 4 -4 4”,“51区”的 “ 5 -5 5 -5 5 5”,把每一位进行累加, “4+5 -4+-5 -4+5 4+-5 -4+5 4+5”–>“9 -9 1 -1 1 9”
5、降维,把算出来的 “9 -9 1 -1 1 9”变成 0 1 串,形成最终的simhash签名。
1.2.2.2 签名距离计算
我们把库里的文本都转换为simhash签名,并转换为long类型存储,空间大大减少。现在我们虽然解决了空间,但是如何计算两个simhash的相似度呢?
我们通过海明距离(Hamming distance)就可以计算出两个simhash到底相似不相似。两个simhash对应二进制(01串)取值不同的数量称为这两个simhash的海明距离。
举例如下: 10101 和 00110 从第一位开始依次有第一位、第四、第五位不同,则海明距离为3。对于二进制字符串的a和b,海明距离为等于在a XOR b运算结果中1的个数(普遍算法)。
1.2.2.3 导入simhash工程
参考项目:https://github.com/CreekLou/simhash.git
导入工程simhash,并打开测试用例。
1.2.2.4 案例整合
需要先把simhash安装到本地仓库
在案例的pom.xml中加入以下依赖
1 | <!--simhash网页去重--> |
修改代码
1 | /** |
1.3 代理的使用
有些网站不允许爬虫进行数据爬取,因为会加大服务器的压力。其中一种最有效的方式是通过ip+时间进行鉴别,因为正常人不可能短时间开启太多的页面,发起太多的请求。
我们使用的WebMagic可以很方便的设置爬取数据的时间(参考第二天的的爬虫的配置、启动和终止)。但是这样会大大降低我们爬取数据的效率,如果不小心ip被禁了,会让我们无法爬去数据,那么我们就有必要使用代理服务器来爬取数据。
1.3.1 代理服务器
代理(英语:Proxy),也称网络代理,是一种特殊的网络服务,允许一个网络终端(一般为客户端)通过这个服务与另一个网络终端(一般为服务器)进行非直接的连接。
提供代理服务的电脑系统或其它类型的网络终端称为代理服务器(英文:Proxy Server)。一个完整的代理请求过程为:客户端首先与代理服务器创建连接,接着根据代理服务器所使用的代理协议,请求对目标服务器创建连接、或者获得目标服务器的指定资源。
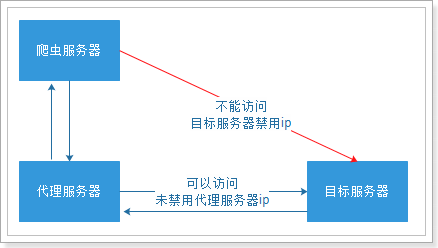
我们就需要知道代理服务器在哪里(ip和端口号)才可以使用。网上有很多代理服务器的提供商,但是大多是免费的不好用,付费的还行。
米扑代理:https://proxy.mimvp.com/free.php
1.3.2 使用代理
WebMagic使用的代理APIProxyProvider。因为相对于Site的“配置”,ProxyProvider定位更多是一个“组件”,所以代理不再从Site设置,而是由HttpClientDownloader设置。
| API | 说明 |
|---|---|
| HttpClientDownloader.setProxyProvider(ProxyProvider proxyProvider) | 设置代理 |
ProxyProvider有一个默认实现:SimpleProxyProvider。它是一个基于简单Round-Robin的、没有失败检查的ProxyProvider。可以配置任意个候选代理,每次会按顺序挑选一个代理使用。它适合用在自己搭建的比较稳定的代理的场景。
如果需要根据实际使用情况对代理服务器进行管理(例如校验是否可用,定期清理、添加代理服务器等),只需要自己实现APIProxyProvider即可。
1 | /** |
2. 查询案例实现
把上一次上课抓取到的招聘数据作为数据源,实现招聘信息查询功能。首先需要把MySQL的数据添加到索引库中,然后再实现查询功能。我们这里使用的是SpringBoot,需要把Spring Data ElasticSearch 和项目进行整合。
2.1 开发准备
需要修改之前的配置,网页去重排除lucene依赖,同时去重的依赖必须放在pom.xml的最下部。因为现在要使用ElasticSearch,需要用到新的lucene依赖。
添加ES依赖和单元测试依赖,并修改以前的去重依赖,pom.xml效果:
1 | <dependencies> |
修改配置文件application.properties,添加以下内容
1 | #DB Configuration: |
2.2 导入数据到索引库
2.2.1 编写pojo
1 | /** |
2.2.2 编写dao
1 | /** |
2.2.3 编写Service
编写Service接口
1 | /** |
编写Service实现类
1 | /** |
2.2.4 编写测试用例
先执行createIndex()方法创建索引,再执行jobData()导入数据到索引库
1 | /** |
2.3 查询案例实现
2.3.1 页面跳转实现
添加静态资源到项目中
2.3.2 编写pojo
1 | /** |
2.3.3 编写Controller
1 | /** |
2.3.4 编写Service
在JobRepositoryService编写接口方法
1 | /** |
在JobRepositoryServiceImpl实现接口方法
1 | //salary: *-* |
2.3.5 编写Dao
在JobRepository编写接口方法
1 | /** |
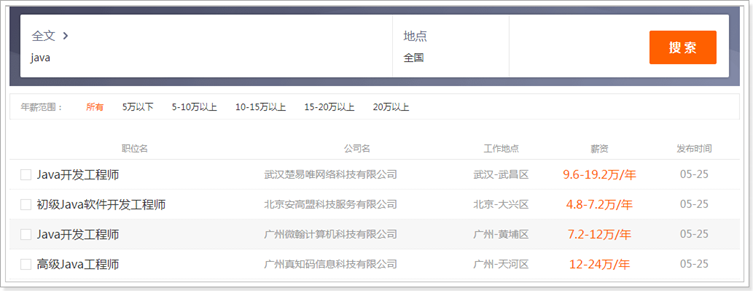
2.3.6 测试
-------------本文结束感谢您的阅读-------------
本文标题: 网络爬虫(三)
本文链接: https://wgy1993.gitee.io/archives/1f29f91c.html
版权声明: 本作品采用 CC BY-NC-SA 4.0 进行许可。转载请注明出处!


