
1. zookeeper源码解析
1.1 下载zookeeper源码,导入IDEA中
下载地址:https://github.com/apache/zookeeper
1.2 启动
根据bin目录下的启动脚本zkServer.sh中加载启动类:QuorumPeerMain类
QuorumPeerMain 中main方法执行initializeAndRun方法
跟进 initializeAndRun方法
1 | protected void initializeAndRun(String[] args) throws ConfigException, IOException, AdminServerException { |
在 initializeAndRun方法中主要做了三件事
加载解析配置文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15File configFile = (new VerifyingFileFactory.Builder(LOG).warnForRelativePath().failForNonExistingPath().build()).create(path);
Properties cfg = new Properties();
FileInputStream in = new FileInputStream(configFile);
try {
cfg.load(in);
configFileStr = path;
} finally {
in.close();
}
/* Read entire config file as initial configuration */
initialConfig = new String(Files.readAllBytes(configFile.toPath()));
parseProperties(cfg);将配置文件加载到
Properties cfg对象中,解析cfg对象。zookeeper所有配置信息封装到一个QuorumPeerConfig对象中启动定时清除任务
PurgeTask继承TimeTask,定时执行run方法中的purge方法1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22static class PurgeTask extends TimerTask {
private File logsDir;
private File snapsDir;
private int snapRetainCount;
public PurgeTask(File dataDir, File snapDir, int count) {
logsDir = dataDir;
snapsDir = snapDir;
snapRetainCount = count;
}
public void run() {
LOG.info("Purge task started.");
try {
PurgeTxnLog.purge(logsDir, snapsDir, snapRetainCount);
} catch (Exception e) {
LOG.error("Error occurred while purging.", e);
}
LOG.info("Purge task completed.");
}
}purge方法主要清除旧的快照和日志文件启动 zk
zookeeper启动方式分为两种:单机启动和集群启动
1
2
3
4
5
6
7
8
9
10if (args.length == 1 && config.isDistributed()) {
//启动集群
runFromConfig(config);
} else {
LOG.warn("Either no config or no quorum defined in config, running "
+ " in standalone mode");
// there is only server in the quorum -- run as standalone
//启动单机
ZooKeeperServerMain.main(args);
}首先我们看看单机启动的源码
main方法调用initializeAndRun方法,initializeAndRun首先加载配置文件,然后执行runFromConfig(config)方法,我们看看runFromConfig具体执行了什么操作1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93public void runFromConfig(ServerConfig config) throws IOException, AdminServerException {
LOG.info("Starting server");
FileTxnSnapLog txnLog = null;
try {
try {
//1.首先开启一下metrics监控
metricsProvider = MetricsProviderBootstrap.startMetricsProvider(config.getMetricsProviderClassName(), config.getMetricsProviderConfiguration());
} catch (MetricsProviderLifeCycleException error) {
throw new IOException("Cannot boot MetricsProvider " + config.getMetricsProviderClassName(), error);
}
ServerMetrics.metricsProviderInitialized(metricsProvider);
// Note that this thread isn't going to be doing anything else,
// so rather than spawning another thread, we will just call
// run() in this thread.
// create a file logger url from the command line args
//2. 创建了FileTxnLog实例和FIleSnap实例,并保存刚启动时候日志数据
txnLog = new FileTxnSnapLog(config.dataLogDir, config.dataDir);
JvmPauseMonitor jvmPauseMonitor = null;
if (config.jvmPauseMonitorToRun) {
jvmPauseMonitor = new JvmPauseMonitor(config);
}
final ZooKeeperServer zkServer = new ZooKeeperServer(jvmPauseMonitor, txnLog, config.tickTime, config.minSessionTimeout, config.maxSessionTimeout, config.listenBacklog, null, config.initialConfig);
txnLog.setServerStats(zkServer.serverStats());
// Registers shutdown handler which will be used to know the
// server error or shutdown state changes.
final CountDownLatch shutdownLatch = new CountDownLatch(1);
zkServer.registerServerShutdownHandler(new ZooKeeperServerShutdownHandler(shutdownLatch));
// Start Admin server
//3. 启动adminServer
adminServer = AdminServerFactory.createAdminServer();
adminServer.setZooKeeperServer(zkServer);
adminServer.start();
//4. 启动NIOServerCnxnFactory
boolean needStartZKServer = true;
//4.1从解析出的配置中配置NIOServerCnxnFactory
if (config.getClientPortAddress() != null) {
cnxnFactory = ServerCnxnFactory.createFactory();
cnxnFactory.configure(config.getClientPortAddress(), config.getMaxClientCnxns(), config.getClientPortListenBacklog(), false);
//4.2启动ZookeeperServer,
cnxnFactory.startup(zkServer);
// zkServer has been started. So we don't need to start it again in secureCnxnFactory.
needStartZKServer = false;
}
if (config.getSecureClientPortAddress() != null) {
secureCnxnFactory = ServerCnxnFactory.createFactory();
secureCnxnFactory.configure(config.getSecureClientPortAddress(), config.getMaxClientCnxns(), config.getClientPortListenBacklog(), true);
secureCnxnFactory.startup(zkServer, needStartZKServer);
}
containerManager = new ContainerManager(zkServer.getZKDatabase(), zkServer.firstProcessor,
Integer.getInteger("znode.container.checkIntervalMs", (int) TimeUnit.MINUTES.toMillis(1)),
Integer.getInteger("znode.container.maxPerMinute", 10000)
);
containerManager.start();
// Watch status of ZooKeeper server. It will do a graceful shutdown
// if the server is not running or hits an internal error.
shutdownLatch.await();
shutdown();
if (cnxnFactory != null) {
cnxnFactory.join();
}
if (secureCnxnFactory != null) {
secureCnxnFactory.join();
}
if (zkServer.canShutdown()) {
zkServer.shutdown(true);
}
} catch (InterruptedException e) {
// warn, but generally this is ok
LOG.warn("Server interrupted", e);
} finally {
if (txnLog != null) {
txnLog.close();
}
if (metricsProvider != null) {
try {
metricsProvider.stop();
} catch (Throwable error) {
LOG.warn("Error while stopping metrics", error);
}
}
}
}启动过程首先开启一下
metrics监控,然后启动admin server,然后启动zk server,我们来看看启动过程ServerCnxnFactory中startup方法调用NettyServerCnxnFactory实现类启动方法1
2
3
4
5
6
7
8public void startup(ZooKeeperServer zks, boolean startServer) throws IOException, InterruptedException {
start();
setZooKeeperServer(zks);
if (startServer) {
zks.startdata();
zks.startup();
}
}启动方法执行操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19public synchronized void startup() {
if (sessionTracker == null) {
createSessionTracker();
}
startSessionTracker();
setupRequestProcessors();
startRequestThrottler();
registerJMX();
startJvmPauseMonitor();
registerMetrics();
setState(State.RUNNING);
requestPathMetricsCollector.start();
notifyAll();
}接下来我们看看集群启动过程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93public void runFromConfig(QuorumPeerConfig config) throws IOException, AdminServerException {
try {
ManagedUtil.registerLog4jMBeans();
} catch (JMException e) {
LOG.warn("Unable to register log4j JMX control", e);
}
LOG.info("Starting quorum peer");
MetricsProvider metricsProvider;
try {
metricsProvider = MetricsProviderBootstrap.startMetricsProvider(config.getMetricsProviderClassName(), config.getMetricsProviderConfiguration());
} catch (MetricsProviderLifeCycleException error) {
throw new IOException("Cannot boot MetricsProvider " + config.getMetricsProviderClassName(), error);
}
try {
ServerMetrics.metricsProviderInitialized(metricsProvider);
ServerCnxnFactory cnxnFactory = null;
ServerCnxnFactory secureCnxnFactory = null;
if (config.getClientPortAddress() != null) {
cnxnFactory = ServerCnxnFactory.createFactory();
cnxnFactory.configure(config.getClientPortAddress(), config.getMaxClientCnxns(), config.getClientPortListenBacklog(), false);
}
if (config.getSecureClientPortAddress() != null) {
secureCnxnFactory = ServerCnxnFactory.createFactory();
secureCnxnFactory.configure(config.getSecureClientPortAddress(), config.getMaxClientCnxns(), config.getClientPortListenBacklog(), true);
}
quorumPeer = getQuorumPeer();
quorumPeer.setTxnFactory(new FileTxnSnapLog(config.getDataLogDir(), config.getDataDir()));
quorumPeer.enableLocalSessions(config.areLocalSessionsEnabled());
quorumPeer.enableLocalSessionsUpgrading(config.isLocalSessionsUpgradingEnabled());
//quorumPeer.setQuorumPeers(config.getAllMembers());
quorumPeer.setElectionType(config.getElectionAlg());
quorumPeer.setMyid(config.getServerId());
quorumPeer.setTickTime(config.getTickTime());
quorumPeer.setMinSessionTimeout(config.getMinSessionTimeout());
quorumPeer.setMaxSessionTimeout(config.getMaxSessionTimeout());
quorumPeer.setInitLimit(config.getInitLimit());
quorumPeer.setSyncLimit(config.getSyncLimit());
quorumPeer.setConnectToLearnerMasterLimit(config.getConnectToLearnerMasterLimit());
quorumPeer.setObserverMasterPort(config.getObserverMasterPort());
quorumPeer.setConfigFileName(config.getConfigFilename());
quorumPeer.setClientPortListenBacklog(config.getClientPortListenBacklog());
quorumPeer.setZKDatabase(new ZKDatabase(quorumPeer.getTxnFactory()));
quorumPeer.setQuorumVerifier(config.getQuorumVerifier(), false);
if (config.getLastSeenQuorumVerifier() != null) {
quorumPeer.setLastSeenQuorumVerifier(config.getLastSeenQuorumVerifier(), false);
}
quorumPeer.initConfigInZKDatabase();
quorumPeer.setCnxnFactory(cnxnFactory);
quorumPeer.setSecureCnxnFactory(secureCnxnFactory);
quorumPeer.setSslQuorum(config.isSslQuorum());
quorumPeer.setUsePortUnification(config.shouldUsePortUnification());
quorumPeer.setLearnerType(config.getPeerType());
quorumPeer.setSyncEnabled(config.getSyncEnabled());
quorumPeer.setQuorumListenOnAllIPs(config.getQuorumListenOnAllIPs());
if (config.sslQuorumReloadCertFiles) {
quorumPeer.getX509Util().enableCertFileReloading();
}
// sets quorum sasl authentication configurations
quorumPeer.setQuorumSaslEnabled(config.quorumEnableSasl);
if (quorumPeer.isQuorumSaslAuthEnabled()) {
quorumPeer.setQuorumServerSaslRequired(config.quorumServerRequireSasl);
quorumPeer.setQuorumLearnerSaslRequired(config.quorumLearnerRequireSasl);
quorumPeer.setQuorumServicePrincipal(config.quorumServicePrincipal);
quorumPeer.setQuorumServerLoginContext(config.quorumServerLoginContext);
quorumPeer.setQuorumLearnerLoginContext(config.quorumLearnerLoginContext);
}
quorumPeer.setQuorumCnxnThreadsSize(config.quorumCnxnThreadsSize);
quorumPeer.initialize();
if (config.jvmPauseMonitorToRun) {
quorumPeer.setJvmPauseMonitor(new JvmPauseMonitor(config));
}
quorumPeer.start();
quorumPeer.join();
} catch (InterruptedException e) {
// warn, but generally this is ok
LOG.warn("Quorum Peer interrupted", e);
} finally {
if (metricsProvider != null) {
try {
metricsProvider.stop();
} catch (Throwable error) {
LOG.warn("Error while stopping metrics", error);
}
}
}
}在
runFromConfig执行过程中主要是QuorumPeer对象属性的赋值并执行start方法,通过查看QuorumPeer类的源码,发现QuorumPeer继承了ZooKeeperThread,而ZooKeeperThread继承了Thread,通过start方法启动了QuorumPeer线程,线程运行执行线程的run方法1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117/*
* Main loop 主循环:集群启动的核心代码
*/
while (running) {
switch (getPeerState()) {
case LOOKING:
LOG.info("LOOKING");
ServerMetrics.getMetrics().LOOKING_COUNT.add(1);
if (Boolean.getBoolean("readonlymode.enabled")) {
LOG.info("Attempting to start ReadOnlyZooKeeperServer");
// Create read-only server but don't start it immediately
final ReadOnlyZooKeeperServer roZk = new ReadOnlyZooKeeperServer(logFactory, this, this.zkDb);
// Instead of starting roZk immediately, wait some grace
// period before we decide we're partitioned.
//
// Thread is used here because otherwise it would require
// changes in each of election strategy classes which is
// unnecessary code coupling.
Thread roZkMgr = new Thread() {
public void run() {
try {
// lower-bound grace period to 2 secs
sleep(Math.max(2000, tickTime));
if (ServerState.LOOKING.equals(getPeerState())) {
roZk.startup();
}
} catch (InterruptedException e) {
LOG.info("Interrupted while attempting to start ReadOnlyZooKeeperServer, not started");
} catch (Exception e) {
LOG.error("FAILED to start ReadOnlyZooKeeperServer", e);
}
}
};
try {
roZkMgr.start();
reconfigFlagClear();
if (shuttingDownLE) {
shuttingDownLE = false;
startLeaderElection();
}
setCurrentVote(makeLEStrategy().lookForLeader());
} catch (Exception e) {
LOG.warn("Unexpected exception", e);
setPeerState(ServerState.LOOKING);
} finally {
// If the thread is in the the grace period, interrupt
// to come out of waiting.
roZkMgr.interrupt();
roZk.shutdown();
}
} else {
try {
reconfigFlagClear();
if (shuttingDownLE) {
shuttingDownLE = false;
startLeaderElection();
}
setCurrentVote(makeLEStrategy().lookForLeader());
} catch (Exception e) {
LOG.warn("Unexpected exception", e);
setPeerState(ServerState.LOOKING);
}
}
break;
case OBSERVING:
try {
LOG.info("OBSERVING");
setObserver(makeObserver(logFactory));
observer.observeLeader();
} catch (Exception e) {
LOG.warn("Unexpected exception", e);
} finally {
observer.shutdown();
setObserver(null);
updateServerState();
// Add delay jitter before we switch to LOOKING
// state to reduce the load of ObserverMaster
if (isRunning()) {
Observer.waitForObserverElectionDelay();
}
}
break;
case FOLLOWING:
try {
LOG.info("FOLLOWING");
setFollower(makeFollower(logFactory));
follower.followLeader();
} catch (Exception e) {
LOG.warn("Unexpected exception", e);
} finally {
follower.shutdown();
setFollower(null);
updateServerState();
}
break;
case LEADING:
LOG.info("LEADING");
try {
setLeader(makeLeader(logFactory));
leader.lead();
setLeader(null);
} catch (Exception e) {
LOG.warn("Unexpected exception", e);
} finally {
if (leader != null) {
leader.shutdown("Forcing shutdown");
setLeader(null);
}
updateServerState();
}
break;
}
}核心逻辑在 while循环中,判断节点的状态,分为
LOOKING、OBSERVING、FOLLOWING、LEADING,当某个QuorumPeerq刚启动时,状态为LOOKING,启动线程将zk节点启动,然后进行leader选举,这是zookeeper的选举算法的核心,leader的选举在org.apache.zookeeper.server.quorum.FastLeaderElection的lookForLeader方法中
1.3 leader选举
1 | // 记录当前server接受其他server的本轮投票信息 |
此处两个变量,一个 recvset,用来保存当前server的接受其他server的本轮投票信息,key为当前server的id,也即是我们在配置文件中配置的myid,而另外一个变量outofelection保存选举结束以后法定的server的投票信息,这里的法定指的是FOLLOWING和LEADING状态的server,不包活OBSERVING状态的server。
更新逻辑时钟,此处逻辑时钟是为了在选举leader时比较其他选票中的server中的epoch和本地谁最新,然后将自己的选票proposal发送给其他所有server。
1 | private void sendNotifications() { |
此方法遍历所有投票参与者集合,将选票信息构造成一个 ToSend对象,分别发送消息放置到队列sendqueue中。同理集群中每一个server节点都会将自己的选票发送给其他server,那么既然有发送选票,肯定存在接受选票信息,并选出leader,接下来我们就来看看每一个server如何接受选票并处理的。
首先我们应该从队列出取出选票信息
1 | //从队列中取出选票信息 |
选出的选票信息封装在一个 Notification 对象中,如果取出的选票为null,我们通过QuorumCnxManager检查发送队列中是否投递过选票,如果投递过说明连接并没有断开,则重新发送选票到其他sever,否则,说明连接断开,重连所有server即可。那么连接没有断开,为什么会收不到选票信息呢,有可能是选票超时时限导致没有收到选票,所有将选票时限延长了一倍。
1 | //校验选票中选举server和选举的leader sever是否合法 |
如果选出的选票 Notification不为null,校验投票server和选举leader是否合法,然后根据选票状态执行
不同分支,选举过程走LOOKING分支,接下来比较选票epoch和当前逻辑时钟,如果选票 epoch>逻辑时钟,说明选票是最新的,自己的选票这一轮已经过时,应该更新当前自己server的逻辑时钟,并清空当前收到的其他server的选票,然后比较自己和选票中谁更适合做leader,发送新的投票给其他所有server。
1 | if (getInitLastLoggedZxid() == -1) { |
如果选票 epoch<逻辑时钟,zk放弃此次选票,不做任何处理。
1 | else if (n.electionEpoch < logicalclock.get()) { |
如果选票 epoch=逻辑时钟,仍然是比较选票和当前自己server谁更适合当leader,并重新更新选票,发送给其他所有的server
1 | else if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, proposedLeader, proposedZxid, proposedEpoch)) { |
接下来将收到的选票放入 recvset的map中保存。
1 | recvset.put(n.sid, new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch)); |
接下来是判断本轮选举是否结束,如果超过半数的,则 leader预选举结束,注意此时还要比较其他少半选票中有没有谁更适合做leader?如果在选票找不到任何一个server比当前server更适合做leader,则更新更新server状态,清空recvqueue队列,确定最终选票并返回,否则将更适合做leader的Notification放回队列开始新一轮的选举。
1 | voteSet = getVoteTracker(recvset, new Vote(proposedLeader, proposedZxid, logicalclock.get(), proposedEpoch)); |
更新状态后,若选票中的服务器状态为 FOLLOWING或者LEADING时,其大致步骤会再次判断选举epoch是否等于逻辑时钟.如果相等,再次盘检查选中的leader过半
1 | if (n.electionEpoch == logicalclock.get()) { |
2. zookeeper应用场景
2.1 配置中心
在平常的业务开发过程中,我们通常需要将系统的一些通用的全局配置,例如机器列表配置,运行时开关配置,数据库配置信息等统一集中存储,让集群所有机器共享配置信息,系统在启动会首先从配置中心读取配置信息,进行初始化。传统的实现方式将配置存储在本地文件和内存中,一旦机器规模更大,配置变更频繁情况下,本地文件和内存方式的配置维护成本较高,使用zookeeper作为分布式的配置中心就可以解决这个问题。
我们将配置信息存在zk中的一个节点中,同时给该节点注册一个数据节点变更的watcher监听,一旦节点数据发生变更,所有的订阅该节点的客户端都可以获取数据变更通知。
2.2 负载均衡
建立server节点,并建立监听器监视servers子节点的状态(用于在服务器增添时及时同步当前集群中服务器列表)。在每个服务器启动时,在servers节点下建立具体服务器地址的子节点,并在对应的字节点下存入服务器的相关信息。这样,我们在zookeeper服务器上可以获取当前集群中的服务器列表及相关信息,可以自定义一个负载均衡算法,在每个请求过来时从zookeeper服务器中获取当前集群服务器列表,根据算法选出其中一个服务器来处理请求。
2.3 命名服务
命名服务是分布式系统中的基本功能之一。被命名的实体通常可以是集群中的机器、提供的服务地址或者远程对象,这些都可以称作为名字。常见的就是一些分布式服务框架(RPC、RMI)中的服务地址列表,通过使用名称服务客户端可以获取资源的实体、服务地址和提供者信息。命名服务就是通过一个资源引用的方式来实现对资源的定位和使用。在分布式环境中,上层应用仅仅需要一个全局唯一名称,就像数据库中的主键。
在单库单表系统中可以通过自增ID来标识每一条记录,但是随着规模变大分库分表很常见,那么自增ID有仅能针对单一表生成ID,所以在这种情况下无法依靠这个来标识唯一ID。UUID就是一种全局唯一标识符。但是长度过长不易识别。
- 在 Zookeeper中通过创建顺序节点就可以实现,所有客户端都会根据自己的任务类型来创建一个顺序节点,例如 job-00000001
- 节点创建完毕后, create()接口会返回一个完整的节点名,例如:job-00000002
- 拼接 type类型和完整节点名作为全局唯一的ID
2.4 DNS服务
2.4.1 域名配置
在分布式系统应用中,每一个应用都需要分配一个域名,日常开发中,往往使用本地HOST绑定域名解析,开发阶段可以随时修改域名和IP的映射,大大提高开发的调试效率。如果应用的机器规模达到一定程度后,需要频繁更新域名时,需要在规模的集群中变更,无法保证实时性。所有我们在zk上创建一个节点来进行域名配置
2.4.2 域名解析
应用解析时,首先从zk域名节点中获取域名映射的IP和端口。
2.4.3 域名变更
每个应用都会在在对应的域名节点注册一个数据变更的watcher监听,一旦监听的域名节点数据变更,zk会向所有订阅的客户端发送域名变更通知。
2.5 集群管理
随着分布式系统规模日益扩大,集群中机器的数量越来越多。有效的集群管理越来越重要了,zookeeper集群管理主要利用了watcher机制和创建临时节点来实现。以机器上下线和机器监控为例:
2.5.1 机器上下线
新增机器的时候,将Agent部署到新增的机器上,当Agent部署启动时,会向zookeeper指定的节点下创建一个临时子节点,当Agent在zk上创建完这个临时节点后,当关注的节点zookeeper/machines下的子节点新加入新的节点时或删除都会发送通知,这样就对机器的上下线进行监控。
2.5.2 机器监控
在机器运行过程中,Agent会定时将主机的的运行状态信息写入到/machines/hostn主机节点,监控中心通过订阅这些节点的数据变化来获取主机的运行信息。
2.6 分布式锁
2.6.1 数据库实现分布式锁
首先我们创建一张锁表,锁表中字段设置唯一约束
1 | CREATE TABLE `lock_record` ( |
定义锁,实现 Lock接口,tryLock()尝试获取锁,从锁表中查询指定的锁记 录,如果查询到记录,说明已经上锁,不能再上锁
1 | //尝试获取锁 |
在 lock方法获取锁之前先调用tryLock()方法尝试获取锁,如果未加锁则向锁表中插入一条锁记录来获取锁,这里我们通过循环,如果上锁我们一致等待锁的释放
1 | //上锁 |
释放锁,即是将数据库中对应的锁表记录删除
1 | //释放锁的操作 |
注意在尝试获取锁的方法 tryLock中,存在多个线程同时获取锁的情况,可以简单通过synchronized解决
2.6.2 redis实现分布式锁
redis分布式锁的实现基于setnx(set if not exists),设置成功,返回1;设置失败,返回0,释放锁的操作通过del指令来完成
如果设置锁后在执行中间过程时,程序抛出异常,导致del指令没有调用,锁永远无法释放,这样就会陷入死锁。所以我们拿到锁之后会给锁加上一个过期时间,这样即使中间出现异常,过期时间到后会自动释放锁。
同时在setnx 和 expire 如果进程挂掉,expire不能执行也会死锁。所以要保证setnx和expire是一个原子性操作即可。redis 2.8之后推出了setnx和expire的组合指令
1 | set key value ex 5 nx |
lock获取锁方法
1 |
|
释放锁
1 |
|
redis 实现分布式锁存在的问题,为了解决redis单点问题,我们会部署redis集群,在 Sentinel 集群中,主节点突然挂掉了。同时主节点中有把锁还没有来得及同步到从节点。这样就会导致系统中同样一把锁被两个客户端同时持有,不安全性由此产生。redis官方为了解决这个问题,推出了Redlock 算法解决这个问题。但是带来的网络消耗较大。
分布式锁的redisson实现:
1 | <dependency> |
获取锁释放锁
1 | Config config = new Config(); |
2.6.3 zookeeper实现分布式锁
原理:zookeeper通过创建临时序列节点来实现分布式锁,适用于顺序执行的程序,大体思路就是创建临时序列节点,找出最小的序列节点,获取分布式锁,程序执行完成之后此序列节点消失,通过watch来监控节点的变化,从剩下的节点的找到最小的序列节点,获取分布式锁,执行相应处理,依次类推……
2.6.3.1 原生实现
首先在ZkLock的构造方法中,连接zk,创建lock根节点
1 | //zk客户端 |
添加 watch监听临时顺序节点的删除
1 | class LockWatcher implements Watcher { |
获取锁操作
1 |
|
释放锁
1 |
|
2.6.3.2 基于 curator实现分布式锁
maven依赖
1 | <dependency> |
锁操作
1 | //创建zookeeper的客户端 |
2.7 分布式队列
队列特性:FIFO(先入先出),zookeeper实现分布式队列的步骤
- 在队列节点下创建临时顺序节点 例如/queue_info/192.168.1.1-0000001
- 调用 getChildren()接口来获取/queue_info节点下所有子节点,获取队列中所有元素
- 比较自己节点是否是序号最小的节点,如果不是,则等待其他节点出队列,在序号最小的节点注册watcher
- 获取 watcher通知后,重复步骤
3. zookeeper 开源客户端curator
3.1 curator简介
curator是Netflix公司开源的一个zookeeper客户端,后捐献给apache,curator框架在zookeeper原生API接口上进行了包装,解决了很多zooKeeper客户端非常底层的细节开发。提供zooKeeper各种应用场景(比如:分布式锁服务、集群领导选举、共享计数器、缓存机制、分布式队列等)的抽象封装,实现了Fluent风格的API接口,是最好用,最流行的zookeeper的客户端。
原生zookeeperAPI的不足:
- 连接对象异步创建,需要开发人员自行编码等待
- 连接没有自动重连超时机制
- watcher一次注册生效一次
- 不支持递归创建树形节点
curator特点:
- 解决session会话超时重连
- watcher反复注册
- 简化开发api
- 遵循Fluent风格的API
- 提供了分布式锁服务、共享计数器、缓存机制等机制
maven依赖:
1 | <dependencies> |
3.2 连接到ZooKeeper
案例:
1 | /** |
3.3 新增节点
案例:
1 | /** |
3.4 更新节点
案例:
1 | /** |
3.5 删除节点
案例:
1 | /** |
3.6 查看节点
案例:
1 | /** |
3.7 查看子节点
案例:
1 | /** |
3.8 检查节点是否存在
案例:
1 | /** |
3.9 watcherAPI
curator提供了两种Watcher(Cache)来监听结点的变化
- Node Cache : 只是监听某一个特定的节点,监听节点的新增和修改
- PathChildren Cache : 监控一个ZNode的子节点. 当一个子节点增加, 更新,删除时, Path Cache会改变它的状态, 会包含最新的子节点, 子节点的数据和状态
案例:
1 | /** |
3.10 事务
案例:
1 | /** |
3.11 分布式锁
InterProcessMutex:分布式可重入排它锁
InterProcessReadWriteLock:分布式读写锁
案例:
1 | /** |
4. zookeeper四字监控命令
zooKeeper支持某些特定的四字命令与其的交互。它们大多是查询命令,用来获取 zooKeeper服务的当前状态及相关信息。用户在客户端可以通过 telnet 或 nc 向zooKeeper提交相应的命令。 zooKeeper常用四字命令见下表 所示:
| 命令 | 描述 |
|---|---|
| conf | 输出相关服务配置的详细信息。比如端口、zk数据及日志配置路径、最大连接数,session超时时间、serverId等 |
| cons | 列出所有连接到这台服务器的客户端连接/会话的详细信息。包括“接受/发送”的包数量、session id 、操作延迟、最后的操作执行等信息 |
| crst | 重置当前这台服务器所有连接/会话的统计信息 |
| dump | 列出未经处理的会话和临时节点 |
| envi | 输出关于服务器的环境详细信息 |
| ruok | 测试服务是否处于正确运行状态。如果正常返回”imok”,否则返回空 |
| stat | 输出服务器的详细信息:接收/发送包数量、连接数、模式(leader/follower)、节点总数、延迟。 所有客户端的列表 |
| srst | 重置server状态 |
| wchs | 列出服务器watches的简洁信息:连接总数、watching节点总数和watches总数 |
| wchc | 通过session分组,列出watch的所有节点,它的输出是一个与 watch 相关的会话的节点列表 |
| mntr | 列出集群的健康状态。包括“接受/发送”的包数量、操作延迟、当前服务模式(leader/follower)、节点总数、watch总数、临时节点总数 |
nc命令工具安装:
1 | #root用户安装 |
使用方式,在shell终端输入:echo mntr | nc localhost 2181
5. zookeeper图形化的客户端工具
ZooInspector下载地址:https://issues.apache.org/jira/secure/attachment/12436620/ZooInspector.zip
解压后进入目录ZooInspector\build,运行zookeeper-dev-ZooInspector.jar
1 | #执行命令如下 |
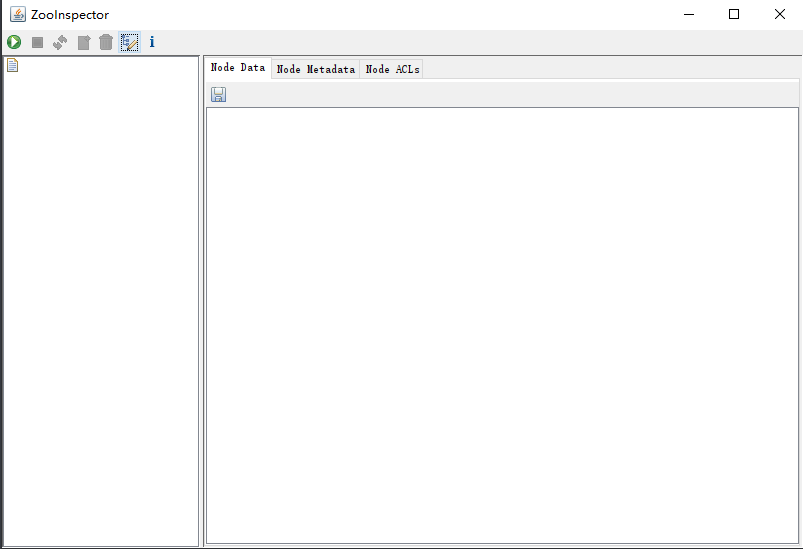
点击左上角连接按钮,输入zk服务地址:ip或者主机名:2181
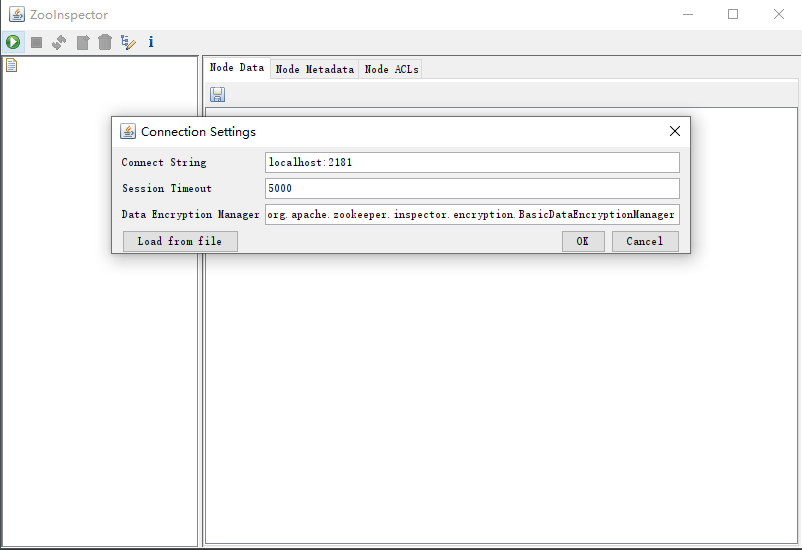
点击OK,即可查看ZK节点信息
-------------本文结束感谢您的阅读-------------
本文标题: zookeeper(二)
本文链接: https://wgy1993.gitee.io/archives/4ebc2ef7.html
版权声明: 本作品采用 CC BY-NC-SA 4.0 进行许可。转载请注明出处!


