
1. SpringData Redis
1.1 SpringData Redis 简介
Redis是一个基于内存的数据结构存储系统,它可以用作数据库或者缓存。它支持多种类型的数据结构,这些数据结构类型分别为String(字符串)、List(列表)、Set(集合)、Hash(散列)和Zset(有序集合)。
SpringData Redis的作用是通过一段简单的配置即可访问redis服务,它的底层是对java提供的redis开发包(比如jedis等)进行了高度封装,主要提供了如下功能:
- 连接池自动管理,提供了一个高度封装的 RedisTemplate类,基于这个类的对象可以对redis进行各种操作
- 针对 jedis客户端中大量api进行了归类封装,将同一类型操作封装为operation接口
- ValueOperations :简单字符串类型数据操作
- SetOperations :set类型数据操作
- ZSetOperations :zset类型数据操作
- HashOperations :map类型的数据操作
- ListOperations :list类型的数据操作
1.2 Redis 环境搭建
1.2.1 安装redis的依赖环境
1 | yum -y install gcc automake autoconf libtool make |
1.2.2 上传安装包
获取到安装包,并将它上传到linux的/usr/local/src/目录下
1.2.3 解压
解压安装包,得到一个redis-5.0.4目录
1 | tar -zxvf redis-5.0.4.tar.gz |
1.2.4 编译
进入redis目录,在目录下执行make命令
1 | cd redis-5.0.4 |
1.2.5 安装
执行安装命令,注意此处指定了安装目录为/usr/local/redis
1 | make PREFIX=/usr/local/redis install |
1.2.6 复制配置文件
将配置文件复制到redis的安装目录的bin目录下
1 | cd /usr/local/redis/bin/ |
1.2.7 修改 redis的配置文件
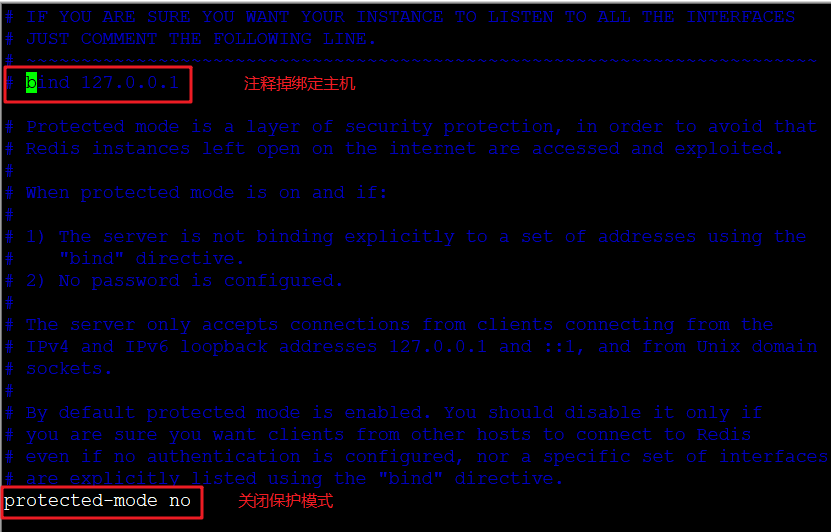
修改redis的配置文件,将注解绑定和保护模式关闭,方便我们从客户端连接测试
1 | vim redis.conf |
1.2.8 启动 redis服务
1 | ./src/redis-server redis.conf |
1.3 SpringData Redis 入门案例
1.3.1 创建工程,引入坐标
1 | <dependencies> |
1.3.2 创建配置文件
1 |
|
1.3.3 测试
1 | /** |
1.4 SpringData Redis 的序列化器
通过Redis提供的客户端查看入门案例中存入redis的数据
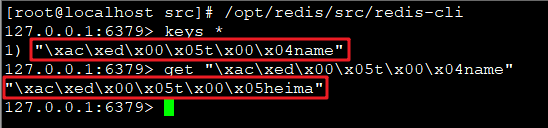
这时候会发现,存入的数据并不是简单的字符串,而是一些类似于二进制的数据,这是怎么回事呢?
原来,SpringData Redis在保存数据的时候,底层有一个序列化器在工作,它会将要保存的数据(键和值)按照一定的规则进行序列化操作后再进行存储。spring-data-redis提供如下几种序列化器:
- StringRedisSerializer: 简单的字符串序列化
- GenericToStringSerializer: 可以将任何对象泛化为字符串并序列化
- Jackson2JsonRedisSerializer: 序列化对象为json字符串
- GenericJackson2JsonRedisSerializer: 功能同上,但是更容易反序列化
- OxmSerializer: 序列化对象为xml字符串
- JdkSerializationRedisSerializer: 序列化对象为二进制数据
RedisTemplate默认使用的是JdkSerializationRedisSerializer对数据进行序列化。
那么如何选择自己想要的序列化器呢?SpringData提供了两种方式:
1、通过配置文件配置
1 | <!--配置Redis的模板--> |
2、通过RedisTemplate设定
1 |
|
1.5 SpringData Redis 运行原理分析
我们从入门案例中已经知道SpringData Redis操作Redis服务器只要是通过RestTemplate实现的,那么RestTemplate底层到底是如何操作redis的呢,下面我们通过源码追踪的形式看一看。
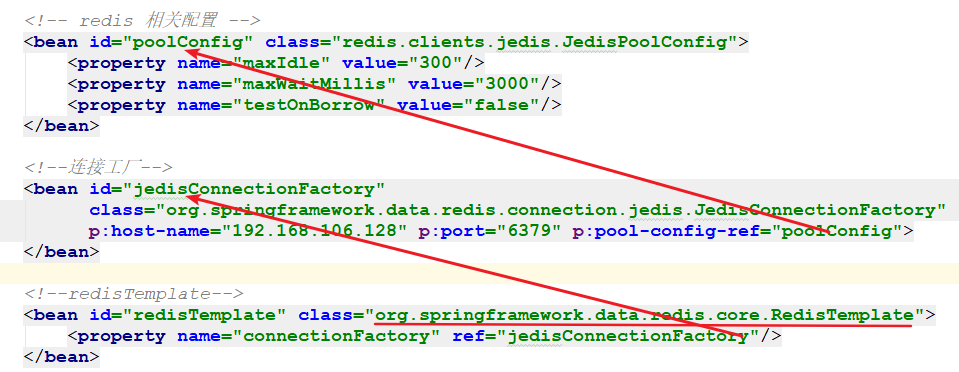
1、首先看配置文件中关于RestTemplate的bean的配置,可以看到在RedisTemplate的bean声明中注入了一个JedisConnectionFactory实例,顾名思义,这个连接工厂是用来获取Jedis连接的,那么通过这种方式RedisTemplate就可以拿到操作Redis服务器的句柄了。
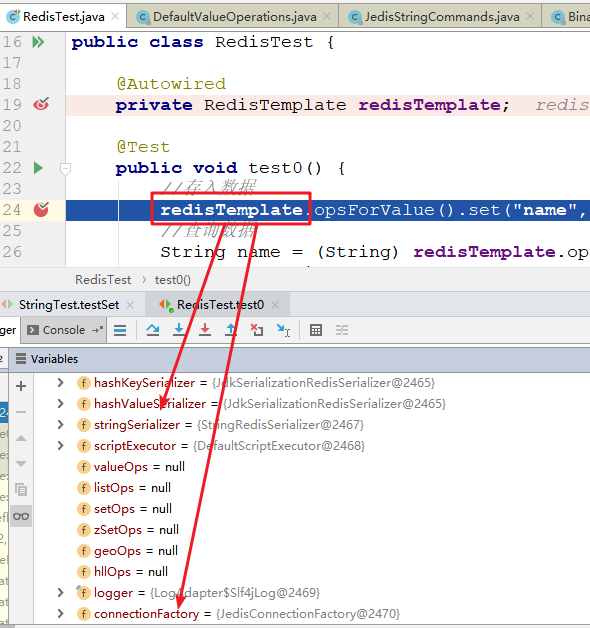
2、使用debug运行入门案例,观察创建好的RestTemplate实例,可以看到里面主要有序列化器和redis的连接信息,基于这些,我们就可以对redis进行操作了
3 、跟踪进入set方法,我们可以看到set方法中使用了一个connection来进行操作,这个connection的类型是JedisConnetion,而这个connection肯定是通过配置文件配置的JedisConnectionFactory产生的,也就是底层开始调用jedis的api了。
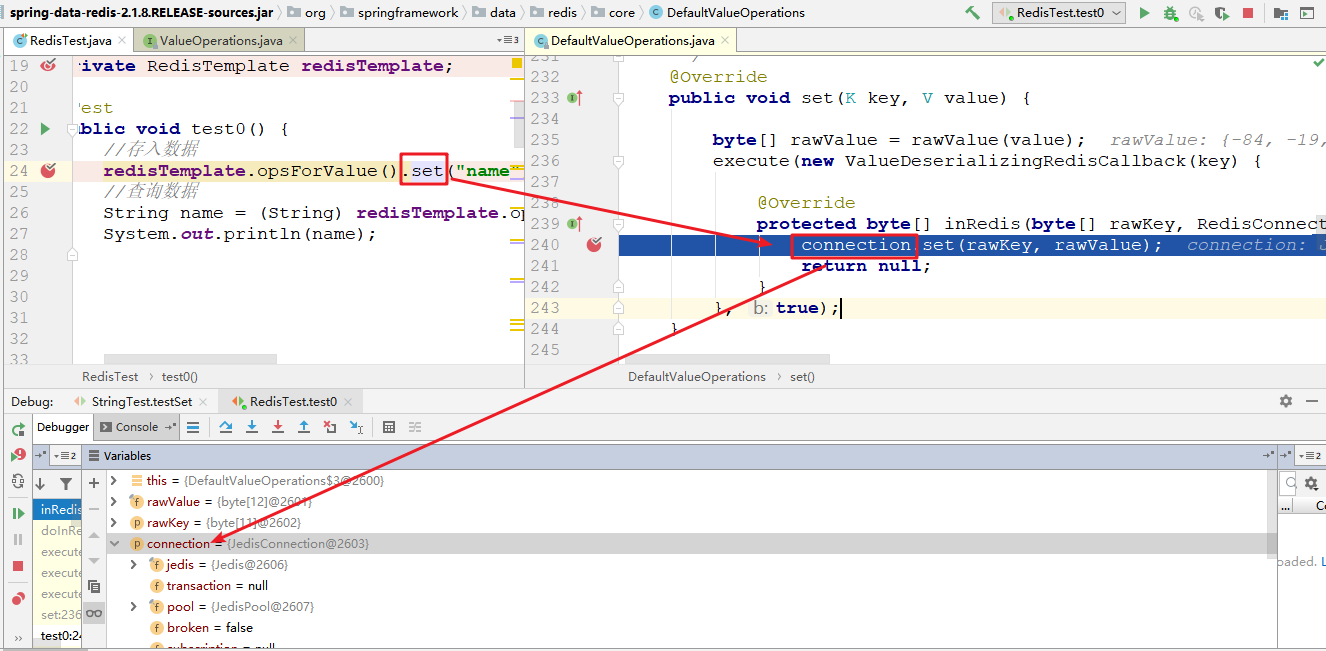
4 、继续追踪set方法,选择JedisStringCommands实现
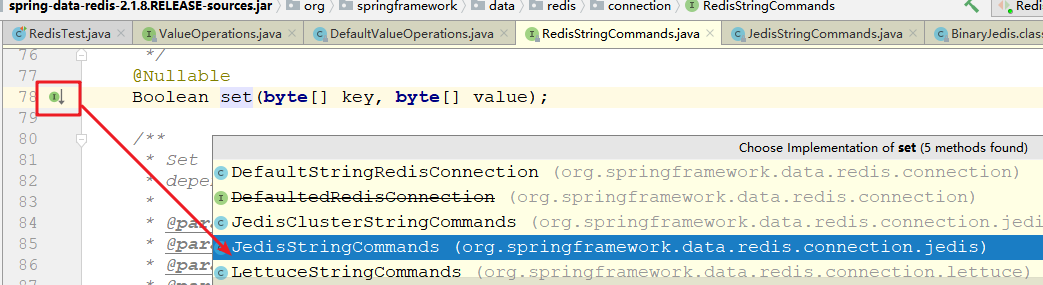
5 、继续之宗set方法,可以看到底层已经获取到了jedis的实例,再调用set方法已经在调jedis的set了
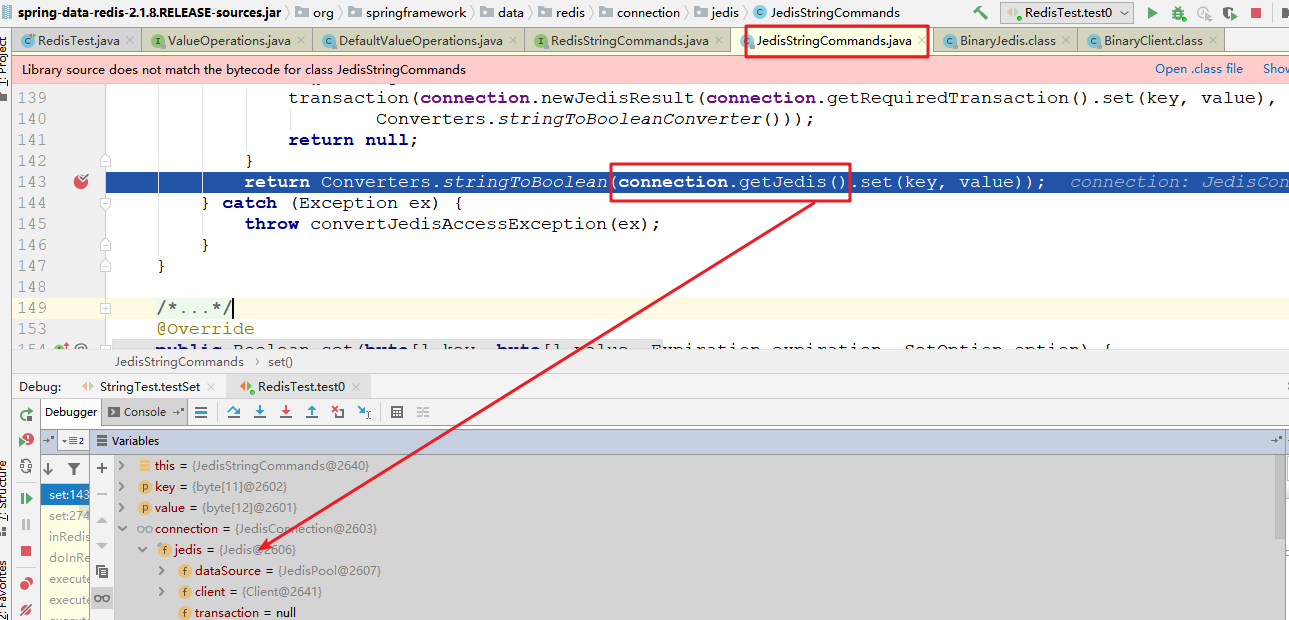
6 、再追踪一步,就会发现,底层最终调用的是jedis的原生API,setCommand方法,这个方法就是jedis提供的对redis的各种操作命令了。

至此,我们的分析完毕。得到的结论就是:
SpringData提供redisTemplate就是在原生的Jedis或者其他操作redis的技术上做的一层封装,它屏蔽掉了这些原生技术的实现细节,统一了调用接口,使得我们的操作更加简单明了。
1.6 SpringData Redis 常见操作
本章节我们来学习如何使用SpringData Redis来操作Redis的各种数据类型.
在Redis中有五种常见类型,SpringData Redis对每一种数据类型都提供了一个xxxOperations的API,他们分别是:
- ValueOperations : 用来操作字符串类型数据
- HashOperations: 用来操作hash类型数据
- ListOperations: 用来操作list类型数据
- SetOperations: 用来操作set类型数据
- ZSetOperations: 用来操作zset类型数据
1.6.1 String类型
1 | /** |
1.6.2 Hash 类型
1 | /** |
1.6.3 List 类型
1 | /** |
1.6.4 Set 类型
1 | /** |
1.6.5 ZSet 类型
1 | /** |
2. Repository和Template的选用
经过前面的章节,我们学习了SpringData家族中jpa和redis的使用,在感受到SpringData技术使用方便的同时,也隐隐约约感觉有点问题,那就是jpa和redis的使用思路好像不是很一致。
我们使用SpringDataJpa的时候,采用了继承SpringData提供的一个接口的形式,即 public interface ArticleDao extends JpaRepository<Article,Integer>,JpaSpecificationExecutor<Article> ,但是使用SpingData Redis的时候,却是使用了在实现类中注入一个 redisTemplate 的方式,那么这两种方式到底有什么关系,用哪个更好呢?
其实这两种方式都可以完成我们对持久层的操作,但是对比两种方式的使用,就会发现:
第一种方式,直接继承xxxRepository接口,可以不必自己去写实现类,而轻松实现简单的增删改查、分页、排序操作,但是对于非常复杂的查询,用起来就比较的费力了;
第二种方式,直接使用xxxTemplate,就需要自己写实现类,但是这样增删改查可以自己控制,对于复杂查询来说,用起来更加得心应手。
所以,两种方式在企业开发中都可能用到,甚至有的项目开发中会同时使用两种方式:对于简单的操作,直接继承Repository接口,对于复杂操作,使用Template完成。所以我们用的时候也要根据实际场景进行灵活选用。
3. SpringData ElasticSearch
3.1 SpringData ElasticSearch 简介
Elasticsearch是一个实时的分布式搜索和分析引擎。它底层封装了Lucene框架,可以提供分布式多用户的全文搜索服务。
Spring Data ElasticSearch是SpringData技术对ElasticSearch原生API封装之后的产物,它通过对原生API的封装,使得程序员可以简单的对ElasticSearch进行各种操作。
3.2 ElasticSearch 环境搭建
3.2.1 安装ElasticSearch
3.2.1.1 准备工作
修改进程限制,编辑/etc/security/limits.conf,添加下面的代码
1 | * soft nofile 65536 |
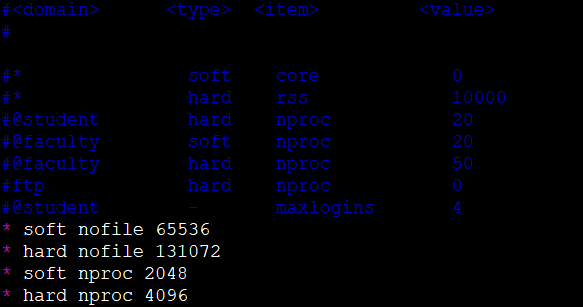
修改系统变量的最大值,编辑/etc/sysctl.conf,添加下面的配置
1 | vm.max_map_count = 655360 |
保存修改之后 ,执行 sysctl -p 命令
1 | sysctl -p |
3.2.1.2 文件上传
上传文件到src目录下
3.2.1.3 文件解压
直接将软件解压到安装目录
1 | tar -zxvf elasticsearch-5.6.8.tar.gz -C /usr/local |
3.2.1.4 添加用户
新增加一个es用户,并将elasticsearch-5.6.8目录的所属用户和用户组改成es
1 | useradd es |
切换到新创建的 es用户,执行后续操作
3.2.1.5 修改配置
编辑配置文件,修改数据文件和日志文件的存储位置以及es的绑定地址
1 | cd /usr/local/elasticsearch-5.6.8/config/ |
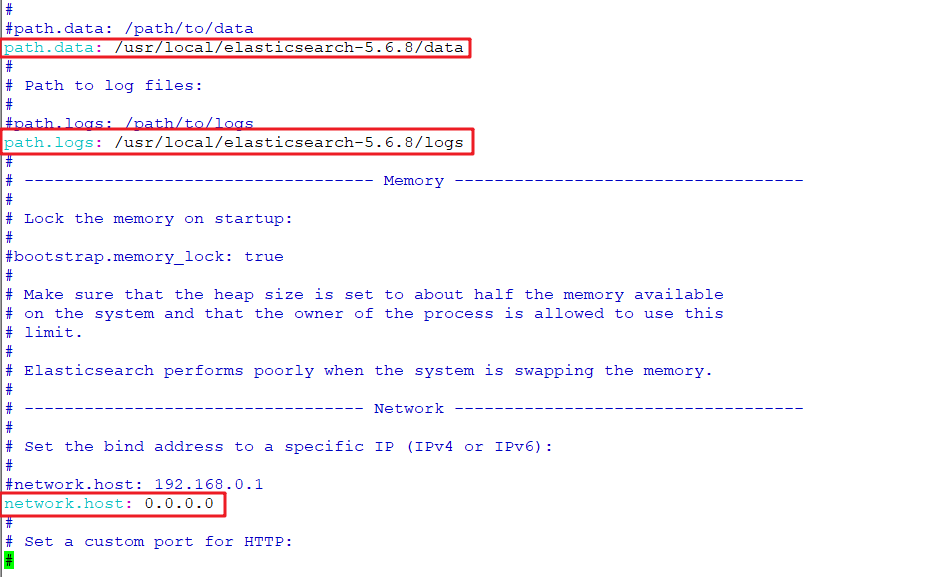
3.2.1.6 启动 elasticSearch
1 | cd /usr/local/elasticsearch-5.6.8/bin/ |
3.2.1.7 访问测试
通过服务器的9200端口访问,得到下面的结果,证明安装成功.
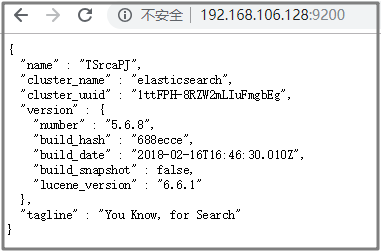
3.2.2 安装 Head插件
3.2.2.1 安装nodeJS
将nodeJS的安装包上传到/usr/local/src下,然后解压到/usr/local下,然后将npm和node建立软连接到/usr/local/bin/下
1 | tar -zxvf node-v10.16.0-linux-x64.tar.gz -C /usr/local/ |
3.2.2.2 安装 cnpm
1 | npm install -g cnpm --registry=https://registry.npm.taobao.org |
3.2.2.3 安装 grunt
1 | npm install -g grunt-cli |
3.2.2.4 安装 head插件
上传head插件到/usr/local/src/下,然后解压到/usr/local下
1 | unzip elasticsearch-head-master.zip |
3.2.2.5 安装 head插件所需依赖
1 | cd /usr/local/elasticsearch-head-master |
3.2.2.6 修改 elasticsearch的配置
编辑配置文件:/usr/local/elasticsearch-5.6.8/config/elasticsearch.yml,添加跨域请求允许,即增加以下两行:
1 | http.cors.enabled: true |
修改完毕之后 ,要对elasticsearch进行重启
3.2.2.7 启动head
在head目录下启动插件
1 | grunt server |
3.2.2.8 访问测试
通过服务器的9100端口访问,得到下面的结果,证明安装成功.

3.2.3 安装 IK分词器
3.2.3.1 说明
ES默认的中文分词器是将每一个汉字作为一个词,这显然不合适,而IK分词是一款国人开发的相对简单的中文分词器,它包含大量的中文词,而且支持自定义分词。
ik分词器提供的分词规则:
- ik_max_word :会将文本做最细粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为“中华人民共和国、中华人民、中华、华人、人民共和国、人民、共和国、大会堂、大会、会堂等词语。
- ik_smart :会做最粗粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为中华人民共和国、人民大会堂
两种分词器使用的最佳实践是:索引时用ik_max_word,在搜索时用ik_smart。即:索引时最大化的将文章内容分词,搜索时更精确的搜索到想要的结果。
3.2.3.2 安装
第一步:下载得到ik分词器的安装包,将其解压得到有一个文件夹,并将文件夹重命名为ik
1 | unzip elasticsearch-analysis-ik-5.6.8.zip |
第二步 :将elastaicsearch文件夹拷贝到elastaicsearch-5.6.8下的plugins目录下,并重命名为ik
1 | cp -r elasticsearch /usr/local/elasticsearch-5.6.8/plugins/ik |
第三步 :重新启动elasticsearch即可加载IK分词器
第四部:测试
http://服务地址:9200/_analyze?analyzer=ik_smart&pretty=true&text=我是程序员
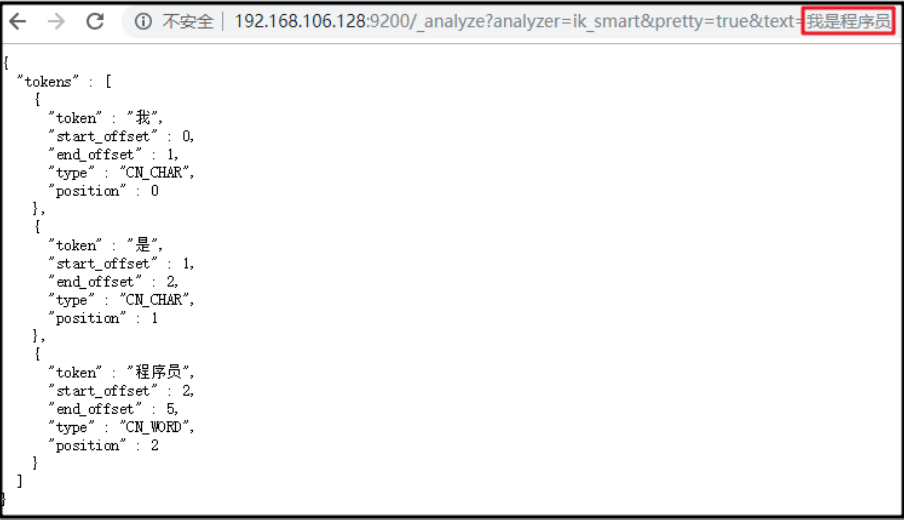
3.3 ElasticSearch 基础知识回顾
3.3.1 核心概念
3.3.1.1 索引 index
一个索引就是一个拥有几分相似特征的文档的集合。索引就类似于关系型数据库中的库的概念。
3.3.1.2 类型 type
一个类型是索引中的一个逻辑上的分类/分区。类型就类似于关系型数据库中的数据表的概念。
3.3.1.3 映射 mapping
映射是对类型中的字段的限制。映射就类似于关系型数据库中的数据表结构的概念。
3.3.1.4 文档 document
一个文档是一个可被索引的基础信息单元。文档就类似于关系型数据库中的行的概念。
1 | ElasticSearch跟关系型数据库中概念的对比: |
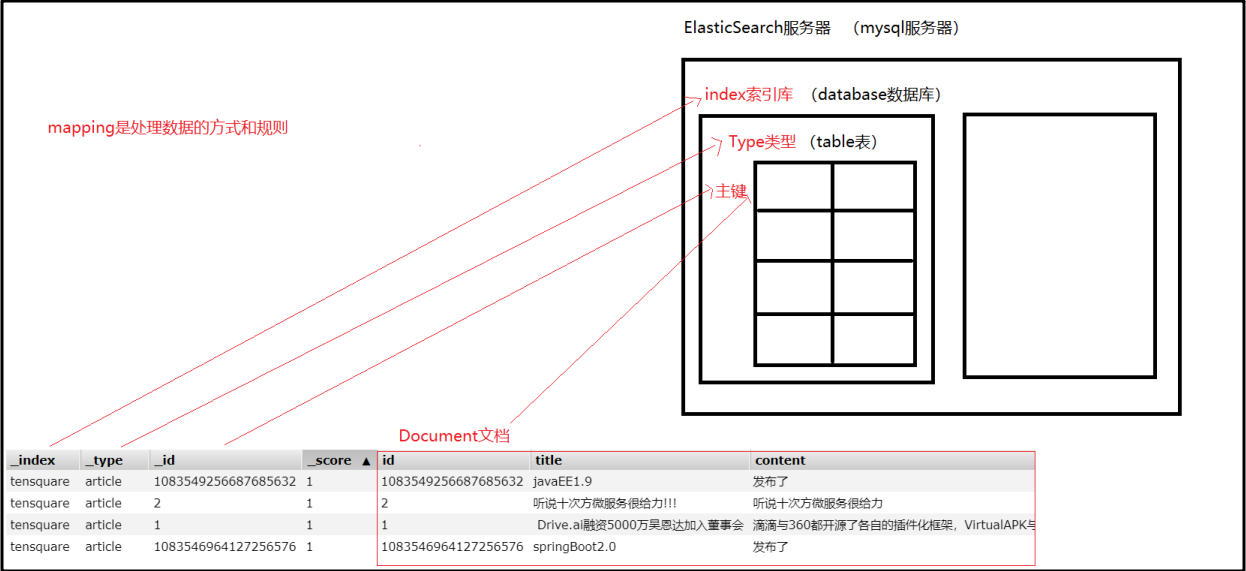
3.3.2 常见操作
3.3.2.1 创建工程,引入坐标
1 | <dependencies> |
3.3.2.2 操作测试
1 | /** |
3.4 SpringData ElasticSearch 入门案例
3.4.1 目标
通过SpringData ES技术向ElasticSearch数据库存储一条数据
3.4.2 创建工程,引入坐标
1 | <dependencies> |
3.4.3 添加配置文件
1 |
|
3.4.4 创建实体类
1 | /** |
3.4.5 自定义 dao接口
1 | /** |
3.4.6 测试
1 | /** |
3.5 SpringData ElasticSearch 实现CRUD操作
3.5.1 增删改
1 | /** |
3.5.2 接口方法查询
1 | /** |
3.5.3 命名规则查询
es的命名规则跟jpa基本一致,常见的如下:
| 关键字 | 命名规则 | 解释 | 示例 |
|---|---|---|---|
| and | findByField1AndField2 | 根据Field1和Field2获得数据 | findByTitleAndContent |
| or | findByField1OrField2 | 根据Field1或Field2获得数据 | findByTitleOrContent |
| is | findByField | 根据Field获得数据 | findByTitle |
| not | findByFieldNot | 根据Field获得补集数据 | findByTitleNot |
| between | findByFieldBetween | 获得指定范围的数据 | findByPriceBetween |
| lessThanEqual | findByFieldLessThan | 获得小于等于指定值的数据 | findBy |
下面,我们在dao接口中按照规则进行自定义查询方法
1 | /** |
添加测试方法
1 | /** |
4. SpringData MongoDB
4.1 SpringData MongoDB 简介
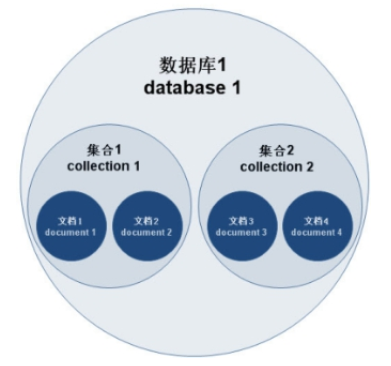
MongoDB 是一个跨平台的,面向文档的数据库,是非关系数据库当中功能最丰富,最像关系数据库的产品。它支持的数据结构非常松散,是类似 JSON 的一种格式,因此可以存储比较复杂的数据类型。
MongoDB主要由文档(document)、集合(collection)、数据库(database)三部分组成
- 文档( document)就相当于关系数据库中的一行记录
- 多个文档组成一个集合( collection),相当于关系数据库的表
- 多个集合组织在一起,就是数据库( database),一个 MongoDB 实例支持多个数据库
SpringData MongoDB是SpringData技术封装了mongodb-driver技术之后的产物,它可以用更加简单的方式操作MongoDB。
4.2 MongoDB 环境搭建
4.2.1 解压
上传文件到服务器,然后将其解压到/usr/local下
1 | tar -zxvf mongodb-linux-x86_64-rhel70-4.0.10.tgz -C /usr/local/ |
4.2.2 创建需要的目录
进入软件的安装目录下,创建数据存储和日志存储目录
1 | cd /usr/local/mongodb-linux-x86_64-rhel70-4.0.10/ |
4.2.3 创建配置文件
进入bin目录,创建mongodb的配置文件mongo.conf ,文件内容如下:
1 | dbpath=/usr/local/mongodb-linux-x86_64-rhel70-4.0.10/data |
4.2.4 启动 mongodb
使用./mongod -f mongo.conf 启动服务,见到类似如下提示,证明启动成功
1 | ./mongod -f mongo.conf |
4.3 SpringData MongoDB 入门案例
4.3.1 目标
通过SpringData技术向Mongodb数据库存储一条数据
4.3.2 创建工程,引入坐标
1 | <dependencies> |
4.3.3 创建配置文件
1 |
|
4.3.4 创建实体类
1 | /** |
4.3.5 自定义 dao接口
1 | /** |
4.3.6 测试
1 | /** |
4.4 SpringData MongoDB 实现CRUD操作
4.4.1 增删改
1 | /** |
4.4.2 简单查询
1 | /** |
4.4.3 命名规则查询
定义接口
1 | /** |
测试方法
1 | /** |
5. 综合案例
5.1 案例说明及思路分析
5.1.1 案例目标
通过一个【文章】案例来综合使用SpringData技术,案例中将涉及到jpa、redis、es、mongo的使用,可以很好的将前面章节所学知识点加以练习巩固。
5.1.2 涉及技术分析
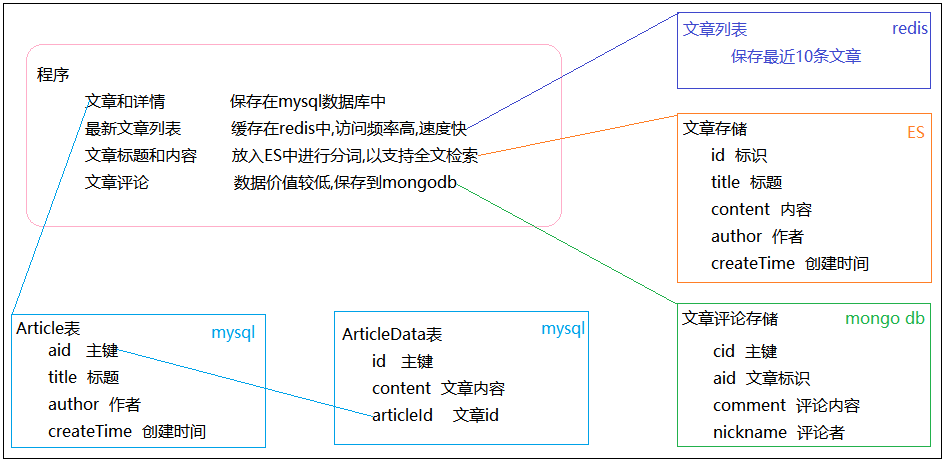
案例以常见网站中的文章管理和查询为背景,涉及到文章内容、最新文章列表、文章评论、文章检索等功能,下面具体分析:
- 文章内容分为文章基础和文章详情两部分,分别存储在 mysql的文章表和文章详情表中
- 最新文章列表展示的是热点数据,访问量比较大,采用 redis存储
- 文章评论数据量大,数据价值较低,存放在 mongodb中
- 全文检索使用 ES实现,本次直接向ES中插入测试数据测试,后期可以考虑使用logstash从数据库同步
5.1.3 功能分析
5.1.3.1 数据后台管理
| 功能 | mysql | redis | mongodb | ES |
|---|---|---|---|---|
| 添加文章 | 添加数据 | 清空缓存 | 添加数据 | |
| 修改文章 | 修改数据 | 清空缓存 | 修改数据 | |
| 删除文章 | 删除数据 | 清空缓存 | 删除文章评论 | 删除数据 |
| 添加评论 | 添加文章评论 | |||
| 删除评论 | 删除文章评论 |
5.1.3.2 数据查询功能
| 功能 | mysql | redis | mongodb | ES |
|---|---|---|---|---|
| 查询最新文章 | 当redis中不存在时来数据库查 | 先从redis查,没有再去数据库查,查到以后放入redis | ||
| 查询文章评论 | 根据文章标识从mongo中获取评论数据 | |||
| 文章检索 | 使用es实现文章检索功能 |
5.2 代码实现
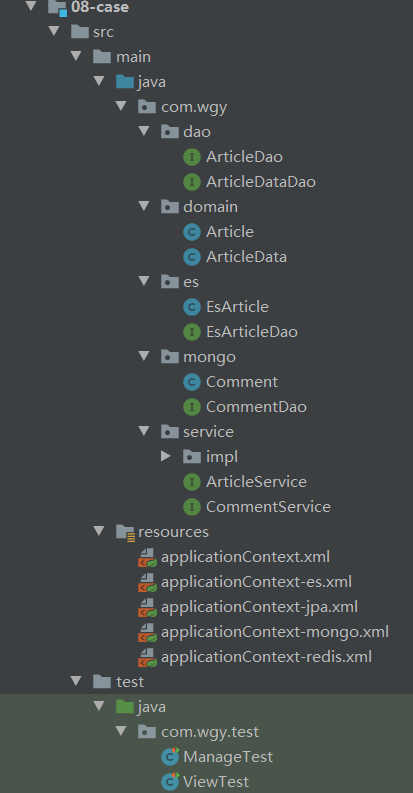
5.2.1 项目结构说明
本次案例采用Spring为核心骨架,使用SpringData实现持久层操作,采用junit进行功能测试,完整项目结构如下图所示
5.2.2 创建工程,引入坐标
1 | <dependencies> |
5.2.3 加入配置文件
5.2.3.1 jpa 配置文件
1 |
|
5.2.3.2 redis 配置文件
1 |
|
5.2.3.3 es 配置文件
1 |
|
5.2.3.4 mongo 配置文件
1 |
|
5.2.3.5 汇总配置文件
1 |
|
5.2.4 创建实体类
5.2.4.1 Article(对应数据库文章表)
1 | /** |
5.2.4.2 ArticleData (对应数据库文章表)
1 | /** |
5.2.4.3 EsArticle ( 对应ES中的文章)
1 | /** |
5.2.4.4 Comment ( 对应mongodb中的评论)
1 | /** |
5.2.5 创建 dao层接口
5.2.5.1 ArticleDao
1 | /** |
5.2.5.2 ArticleDataDao
1 | /** |
5.2.5.3 EsArticleDao
1 | /** |
5.2.5.4 CommentDao
1 | /** |
5.2.6 创建 service层
5.2.6.1 ArticleService接口
1 | /** |
5.2.6.2 ArticleServiceImpl 实现类
1 | /** |
5.2.6.3 CommentService 接口
1 | /** |
5.2.6.4 CommentServiceImpl 实现类
1 | /** |
5.2.7 测试
5.2.7.1 后台管理功能测试
1 | /** |
5.2.7.2 前台查看测试
1 | /** |
-------------本文结束感谢您的阅读-------------
本文标题: SpringData(二)
本文链接: https://wgy1993.gitee.io/archives/dc35f26.html
版权声明: 本作品采用 CC BY-NC-SA 4.0 进行许可。转载请注明出处!


